Резервное копирование информации - один из основных способов её защиты от потери в связи со сбоем техники.
Следует начать с того, что нужно различать резервное копирование системы и резервное копирование отдельных файлов .
Вот несколько простых правил, которые помогут сохранить информацию.
1. Частота копирования.
Рассмотрим сначала резервное копирование операционной системы.
Создание резервной копии поможет вам избежать установки всей системы целиком, её настройки, установки программ и прочего. С усовершенствование компьютерной техники эти методы становятся неактуальны, т.к. любая операционная система сама создаёт резервные копии и восстанавливает их в случае сбоя.
Резервное копирование прочей информации.
Тем, кто постоянно подвергает свою систему каким либо изменениям, которые могут её "убить", лучше всего делать backup файлов каждый раз перед началом подобной работы. Будет достаточно обидно потерять плоды своей работы за несколько дней, забыв сделать очередное резервное копирование перед крахом системы. Конечно, не обязательно делать бэкап перед каждой установкой какой либо новой программы. Обычно бэкап рекомендуется делать в том случае, если вам необходимо сохранить какие либо новые данные, на создание которых было затрачено много времени и средств. Рядовым пользователям хватает одного бэкапа за месяц.
2. Хранение.
Перед тем, как сделать бэкап появляется вопрос - где хранить информацию?
Для начала нужно понять, насколько важна и конфиденциальна данная информация. Если информация представляет ценность только для самого пользователя, то можно использовать следующие способы.
а) Конечно же, можно хранить резервную копию и на самом компьютере, если жёсткий диск разбит на несколько логических. В таком случае, резервную копию сохраняют на любом из дисков, кроме системного. Именно системный диск, на котором стоит операционная система, чаще всего подвержен различным сбоям от установленных на него программ.
б) Хранение на внешнем носителе, например, на флешке, или на съёмном диске, защитит вас от потери информации, если выйдет из строя весь винчестер в компьютере.
в) Хранение информации в интернете.
Всё большую популярность набирают сетевые диски, такие как яндекс-диск и прочие. Хранение данных достаточно удобно, но не безопасно.
Если же информация, содержащаяся в бэкапе, представляет интерес не только для пользователя, то следует задуматься о безопасности доступа к ней. Любой внешней носитель может быть попросту украден.
3. Проверка данных.
После того, как сделан бэкап, необходимо проверить, та ли информация находится в резервной копии и возможно ли её будет использовать. Попросту говоря, пользователь может ошибиться и сделать резервную копию не того файла, который ему нужен.
Встроенные возможности ОС.
как уже упоминалось выше, любая операционная система сама создаёт резервные копии системных файлов.
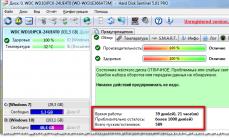
Рассмотри эту функцию на примере операционной системы windows 7. Она называется "Центр архивации и восстановления".
Для того, что б запустить утилиту "Центр архивации и восстановления", делаем следующее:
В открывшемся окне можно сделать полную копию операционной системы, сделать копию отдельных баз данных, или восстановить файлы после сбоя системы.
Данный сервис полностью удовлетворяет потребности обычных пользователей.
Достаточно после сбоя найти свою резервную копию, запустить её, дальше система сама подскажет, какие действия нужно сделать.
Если же пользователя всё таки не устраивает стандартный способ создания резервных копий, то существует множество платных и бесплатных утилит, которые помогут сделать резервную копию.
Приведём наиболее популярные программы для создания резервных копий.
Тройка лучших платных программ:
- Norton Ghost
- Paragon Backup & Recovery
- Acronis True Image Home
Бесплатные программы:
- FBackup 4.8
- File Backup Watcher Free 2.8
- Back2zip 125
- The Copier 7.1
- Comodo BackUp 1.0.2
Из списка перечисленных бесплатны программ можно выбрать любую, которая больше всего подходит по роду и активности пользования компьбтером. Самая "слабая" программа для копирования File Backup Watcher Free 2.8, но у этой программы есть один большой плюс - создавать образы ISO. Back2zip подходит тем, кому редко приходится сталкиваться с резервным копирование, и копировать по сути то почти нечего. The Copier достаточно сложен в работе, но может помочь зарезервировать до 300 гигов данных.
Comodo BackUp - одна из профессиональных программ, которая поможет вам создавать резервные копии документов, настраивать параметры автоматического создания резервных копий и отправки их на внешний ресурс или на FTP сервер.
Клонирование дисков.
Наверное все сталкивались с проблемой, когда на диске заканчивается свободно место.
Что же делать, если удалять уже нечего, а места всё равно не хватает?
Приходится покупать новый винчестер большей ёмкости. Хорошо если есть место в системном блоке для второго винчестера, но что делать, если можно только заменить один винчестер на другой? Нужно как-то перенести все данные со старого винчестера на новый винчестер. Сделать это позволяют специальные программы по клонированию дисков.
Самая распространённая - Acronis 2011 , которая помогает качественно провести клонирование диска.
В данной программе есть 2 режима клонирования. Ручной и автоматический.
В ручном режиме пользователь может выбрать те области, которые необходимо копировать. Ход выполнения процесса отображается в окне программы. После завершения работы программа запросит перезагрузить компьютер, после этого можно будет поменять старый винчестер на новый.
Следующей по популярности идёт программа HDClone . Принцип действия практически такой же. Разница только в цене продукта и в немного урезанном функционале.
Третье место занимает R-Drive Image
Достаточно простая в использовании программа с пошаговым пользовательским интерфейсом. Основное преимущество - дешевизна данного продукта.
Существует так же множество бесплатных аналогичных программ, не уступающих по функциональности вышеперечисленным программам. Примером такой программа может быть Clonezilla и PC Disk Clone Free 8.0. Существует так же платный аналог второй программы.
RAID массивы. Нет, не защита от насекомых.
RAID был создан в 1987 году А. Петтерсоном, А. Гибсоном и Катцом. Первоначально RАID - «redundant array of inexpensive disks» переводилось "запасной массив недорогих дисков". Позже, с увеличением цены на винчестеры, RAID стала носить смысл "redundant array of independent disks", т.е. " запасной массив независимых дисков".
Ранее RAID массивы использовались только для серверов, но сейчас с постоянным развитием техники, RAID массивы используются и для домашних компьютеров.
RAID массив предназначен для ускорения работы компьютера и увеличения надёжности защиты и хранения данных. В зависимости от конфигурации выбора RAID массива зависит увеличение скорости работы компьютера или надёжности сохранения данных.
RAID массив работает следующим образом: специальный контроллер управляет набором винчестеров, которые являются одним логическим диском. Операции записи/воспроизведения производятся параллельно, что обеспечивает высокую производительность. Все записи дублируются и создаются контрольные суммы, это повышает надёжность хранения данных.
существует несколько моделей RAID массивов.
RAID 0 - дисковый массив повышенной производительности с чередованием, без отказоустойчивости;
RAID 1 - зеркальный дисковый массив;
RAID 2 зарезервирован для массивов, которые применяют код Хемминга;
RAID 3 и 4 - дисковые массивы с чередованием и выделенным диском чётности;
RAID 5 - дисковый массив с чередованием и «невыделенным диском чётности»;
RAID 6 - дисковый массив с чередованием, использующий две контрольные суммы, вычисляемые двумя независимыми способами;
RAID 10 - массив RAID 0, состоящий из массивов RAID 1;
RAID 50 - массив RAID 0, состоящий из массивов RAID 5;
RAID 60 - массив RAID 0, состоящий из массивов RAID 6.
Здравствуйте друзья! В прошлой статье мы с вами , а как быть в том случае, если один жёсткий диск уже заполнен файлами и нам нужно создать для него зеркало. Предлагаю сегодня этим и заняться. Перед работой коротко напомню Вам о том, что такое RAID-массив или Зеркалирование (mirroring).
Принцип работы RAID массива это дублирование информации, простыми словами, в вашем компьютере для хранения файлов будет использоваться два винчестера, которые будут полностью копировать друг друга, если вы записали какой-либо файл на первый жёсткий диск, то он также скопируется и на второй диск. Делается это для безопасности вашей информации и если один жёсткий диск вдруг сломается, то все файлы останутся в целости и сохранности на другом винчестере! Один единственный недостаток RAID 1 массива в том, что два ваших жёстких диска будут работать как один, например, при установке в системный блок двух винчестеров в объёме по 1ТБ, в операционной системе они оба определятся как один жёсткий диск объёмом 1 ТБ.
- Примечание : Читайте следующую статью и этого раздела " "
Итак, представим ситуацию, у вас на компьютере установлено два жёстких диска: твердотельный накопитель с Windows 8.1, а также простой жёсткий диск объёмом 250 ГБ с важнейшими файлами, которые вам ни в коем случае нельзя потерять, значит создаём самый простой RAID 1-массив из двух жёстких дисков, то есть покупаем ещё один жёсткий диск на 250 ГБ и устанавливаем его в системный блок.
После этого включаем компьютер и после загрузки операционной системы идём в "Управление дисками" и видим три жёстких диска:
Диск 0 - твердотельный накопитель SSD, диск C: с Windows 8.1.
Диск 1 - обычный HDD (Новый том (D:) объёмом 250 ГБ, с вашими файлами, для него и будем создавать зеркало.
Диск 2 - чистый HDD, также объёмом 250 ГБ, он и будет зеркалом Диска 1.
Объём дисков не обязательно должен быть одинаковым, главное, чтобы зеркало не было меньше в объёме диска, с которого оно создаётся.
Щёлкаем на Диске 1 правой мышью и выбираем Преобразовать в Динамический диск.

Убеждаемся, что диск выбран правильно. ОК.

Преобразовать


Диск 1 (Новый том (D:) преобразован в Динамический диск, с нашими файлами ничего не случилось, они доступны.
Щёлкаем на Новом томе (D:) правой мышью и выбираем Добавить зеркало ,

Выделяем Диск 2 левой мышью и жмём на кнопку Добавить зеркальный том.


Происходит процесс синхронизации содержимого жёстких дисков, вся информация с Нового тома (D:) копируется на зеркало .

"Управления дисками" сообщает, что синхронизация завершена, диски исправны и можно работать.

Окно "Этот компьютер", RAID 1-массив представлен как один том.
Многим компаниям требуются сервера с высокопроизводительной дисковой подсистемой большой емкости, которая достигается за счет использования большого количества высокопроизводительных дисков. Имеем случай, когда компания использовала решение из 10 HDD с интерфейсом SAS емкостью 600 GB, организованных в массив RAID 50 (полезная емкость массива 600*8=4800 GB). Данный RAID 50 представляет из себя комбинированный массив, который рассматриваем как два массива RAID 5, объединенных в массив RAID 0. Данное решение позволяет получить более высокую скорость записи на массив в сравнении с обычным RAID 5 с таким же количеством дисков-участников, потому что для формирования блока четности требуется меньшее число операций чтения с дисков участников (скоростью расчета самого блока четности можно пренебречь в силу того, что он представляет весьма малую нагрузку для современных RAID контроллеров). Также в RAID 50 в некоторых случаях отказоустойчивость будет выше, так как допустима потеря до двух дисков (при условии, что диски из разных массивов RAID 5, входящих в данный RAID). В рассматриваемом нами случае со слов системного администратора произошел отказ 2 дисков, которые привели к остановке RAID массива. Затем последовали действия системного администратора и сервисного отдела компании продавца сервера, которые не могут быть описаны в силу сбивчивых и противоречащих друг другу показаний.
В нашем случае диски пронумерованы представителем заказчика от 0 до 9 со словами: «именно в таком порядке они были использованы в массиве, и никто их местами не менял». Данное утверждение подлежит обязательной проверке. Также мы были поставлены в известность, что данный массив использовался в качестве хранилища для ESXi сервера, и на нем должно содержаться несколько десятков виртуальных машин.
Перед тем, как начать любые операции над дисками из массива, необходимо проверить их физическую целостность и исправность, а также создать копии и далее работать исключительно с копиями для безопасного проведения работ. При наличии серьезно поврежденных накопителей рассмотреть необходимость проведения работ по извлечению данных, то есть если серьезно поврежден только один накопитель, то необходимо выяснить посредством анализа массива, собранного из оставшихся дисков, содержал ли проблемный HDD актуальные данные, или им нужно пренебречь и получить недостающие данные за счет XOR операции над остальными участниками одного из RAID 5, в который входил данный диск.
Было выполнено создание копий, в результате которого выяснилось, что 4 накопителя имеют дефекты между LBA 424 000 000 и LBA 425 000 000, выражается это в виде нечитаемых нескольких десятков секторов на каждом из проблемных дисков. Непрочитанные сектора в копиях заполняем паттерном 0xDE 0xAD для того, чтобы потом была возможность идентификации пострадавших данных.
Первичный анализ подразумевает идентификацию RAID контроллера, к которому были подключены диски, точнее идентификацию расположения метаданных RAID контроллера, чтобы эти области не включать при сборке в массив.
В данном случае в последнем секторе каждого из дисков обнаруживаем характерные 0xDE 0x11 0xDE 0x11 c дальнейшей пометкой бренда RAID контроллера. Метаданные данного контроллера располагаются исключительно в конце LBA диапазона, какие-либо буферные зоны в середине диапазона данным контроллером не используются. На основании этого и предыдущих данных следует вывод, что сбор массива должен начинаться с LBA 0 каждого из дисков.
Зная, что суммарная емкость массива более 2 TB, проводим поиск в LBA 0 каждого из дисков таблицы разделов (защитной MBR)

и GPT заголовка в LBA 1.

В этом случае данных структур не обнаружено. Данные структуры обычно становятся жертвами необдуманных действий обслуживающего сервер персонала, который не отрабатывал ситуации отказа системы хранения данных и не изучал особенностей работы конкретного RAID контроллера.
Для дальнейшего анализа особенностей массива необходимо произвести на одном из дисков поиск регулярных выражений монотонно возрастающих последовательностей. Это могут быть как таблицы FAT или достаточно большой фрагмент MFT , так и иные удобные для анализа структуры. Зная, что на данном массиве содержались виртуальные машины с ОС Windows, мы можем предположить, что внутри данных машин использовалась файловая система NTFS . На основании этого проводим поиск записей MFT по характерному регулярному выражению 0x46 0x49 0x4C 0x45 с нулевым смещением относительно 512-байтного блока (сектора). В нашем случае после LBA 2 400 000 (1,2GB) обнаруживается достаточно протяженный (более 5000 записей) фрагмент MFT. В нашем случае размер записи MFT стандартный и составляет 1024 байт (2 сектора).

Локализуем границы найденного фрагмента с записями MFT и проверим наличие фрагмента с записями MFT в этих границах на остальных дисках-участниках массива (границы могут чуть-чуть отличаться, но не более чем на размер блока, используемого в RAID массиве). В нашем случае наличие записей MFT подтверждается. Листаем записи с анализом номеров (номер DWORD располагается по смещению 0x2C). Анализируем количество блоков, где возрастание номера записи MFT происходит с изменением на единицу, на основании этого рассчитываем размер блока, используемого в данном RAID массиве. В нашем случае размер составляет 0x10000 байт (128 секторов или 64KiB). Далее выберем среди записей MFT какое-либо из мест, где записи MFT или результат их XOR операции симметрично располагаются на всех дисках-участниках и составим матрицу с номерами записей, с которых начинаются блоки массива с удвоенным количеством строк.

По номерам записей определим какие из дисков входят в первый RAID 5, а какие во второй. Проверку корректности выполняем посредством XOR операции. В нашем случае согласно таблицы мы видим, что нумерация дисков представителем заказчика была сделана неверно, так как матрицы обоих массивов отличаются по расположению блока четности (обозначенного как “XOR”). Также видим, что в данном массиве нет задержки четности, так как с каждой строкой меняется положение блока четности.
Заполнив таблицу номерами записей MFT по указанным смещениями с каждого из дисков, можно перейти к заполнению удвоенной матрицы использования дисков. Удвоена она из-за того, что формировать матрицу мы начали в произвольном месте. Следующей задачей ставится определить с какой строки начинается правильная матрица. Задача легко выполнима, если взять первые пять смещений, указанные на рисунке выше и умножить на 8. Далее решить простой пример в виде а=a+b где стартовые значения a=0x0 b=0x280000 (0x280000=0x10000*0x28, где 0x28 является количеством блоков с данными, которые содержатся в матрице использования дисков) и решать его в цикле, пока он не достигнет одного из значений смещений умноженного на 8.
После построения матрицы использования дисков мы можем произвести сбор массива любыми доступными для этого средствами, умеющими работать с матрицей произвольного размера. Но такой вариант сбора массива не будет учитывать актуальности данных на всех дисках, в связи с чем необходимы дополнительные анализы для исключения диска содержащего неактуальные данные (он был первым исключен из массива).
Для определения неактуального диска обычно не требуется полный сбор массива. Достаточно собрать первые 10-100GB и проанализировать найденные структуры. В нашем случае оперируем началом массива из 20GB. Как уже писалось, защитная MBR и GPT на дисках отсутствуют, и, естественно, их нет в собранном массиве, но при поиске достаточно быстро можно найти magic блок VMFS , отняв от его позиции 0x100000 (2048 секторов), получим точку начала VMFS раздела. Определив положение fdc.sf (file descriptor system file), проведем анализ его содержимого. Во многих случаях анализ этой структуры позволит найти место, где присутствуют ошибочные записи. Сопоставив его с матрицей использования дисков, получим номер диска, содержащего неактуальные данные. В нашем случае этого оказалось достаточно и дополнительные аналитические мероприятия не потребовались.
Выполнив сбор массива целиком с компенсацией недостающих данных за счет XOR операции, получили полный образ массива. Зная локализацию дефектов и локализацию файлов виртуальных машин в образе, возможно установить, на какие именно файлы виртуальных машин приходятся дефекты. Выполнив копирование файлов виртуальных машин из VMFS хранилища, можем смонтировать их в ОС как отдельные диски и выполнить проверку целостности файлов, содержащихся в виртуальных машинах посредством поиска файлов, содержащих сектора с паттерном 0xDE 0xAD. Сформировав список поврежденных файлов работу по восстановлению информации из поврежденного RAID 50 можно считать завершенной.
Обращаю внимание, что в данной публикации намеренно не упомянуты профессиональные комплексы для восстановления данных, которые позволяют упростить работу специалиста.
22.02.2009, 01:30
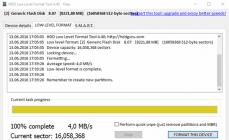
Суть проблемы: имеется массив RAID0. Дискам всего 3 месяца и на одном из них пошли сплошные ошибки. После тестов я убедился в его неисправности и намерен заменить его у продавца. Но т.к. там стоит куча всего, переустановка чего может занять до месяца, а также часть инфы, которую я не успел сохранить на DVD, то возник соответственный вопрос: а могу ли я как-то с помощью прог восстановления данных сделать с него бэкап (или образ), который затем можно будет перенести на новый диск, да так, чтобы RAID массив стал вновь рабочим? Заранее благодарю за ответ!
Добавлено через 31 минуту
Короче, пока нашел способ сделать это с помощью Runtime"s RAID Reconstructor и Captain Nemo Pro. Если все получится, напишу, ну а если нет - буду дальше спрашивать советов.
22.02.2009, 11:49
Alexsan, вообще говоря, здесь очень многое зависит от способа организации RAID и используемого оборудования.
А вот для отказоустойчивых (RAID-1, RAID-5, RAID-10) конфигураций на нормальных аппаратных контроллерах характерна возможность "горячей" замены диска без дополнительных телодвижений с автоматической реконфигурацией массива (не требуется даже остановка работы сервера).
23.02.2009, 03:14
Боюсь, что для полного бэкапа не хватит дискового пространства. У меня там стоят два диска с системой объемом 600 гигабайт и два диска с прогами и данными с суммарным объемом 1,5 террабайта. Так вот накрылся один из больших дисков. Завтра начну попытки восстановления. Пока диски стоят в RAID конфигурации прога Runtime"s RAID Reconstructor их не видит. Вот думаю, как лучше сделать для начала операции - просто отрубить один из дисков (нормальный), либо разрушить RAID-массив через меню? Во втором случае боюсь могут возникнуть проблемы с его восстановлением, т.к. в меню RAID нет опции разделения массива только двух дисков и при ее использовании разрушиться также массив нормальных системных дисков. Так что вопрос такой: как лучше подготовиться к операции восстановления - механически отсоединить диск, чтобы он начал читаться как IDE или временно разделить RAID-массив через меню RAID?
23.02.2009, 09:41
Alexsan, ещё раз повторяю -
Правильным способом является бэкап всего RAID целиком, пересоздание массива заново после замены диска и восстановление данных из бэкапа.
для полного бэкапа не хватит дискового пространстваЛибо эти данные необходимы и место найдётся (винчестеры на 1,5Тб есть в продаже), либо вы их потеряете с весьма большой вероятностью.
23.02.2009, 12:22
Alexsan, ещё раз повторяю -
В любом другом случае я лично очень сомневаюсь в возможности успешного завершения операции по замене винчестера в RAID-0.
Либо эти данные необходимы и место найдётся (винчестеры на 1,5Тб есть в продаже), либо вы их потеряете с весьма большой вероятностью.
Как я уже неоднократно писал (да и не только я), RAID-0 - редкостная пакость, и хранить на нём что-либо ценное нельзя...
Из-за дефекта диска сделать бэкап целиком не выходит по одной причине - Runtime"s RAID Reconstructor не видит эти диски, если в БИОСе активирована функция RAID. Получается только считать каждый диск по отдельности, когда выставляешь режим IDE - в этом случае они доступны. Попробую забэкапить дефектный диск на другом компе. Кстати, вычитал, что причиной ошибки может быть также не физическое повреждение диска, а ошибочная запись данных в запрещенные служебные сектора. Так что после бэкапа попробую нулевое форматирование и повторное тестирование. Правда, на этот счет у меня имеется негативный опыт пятилетней давности - дефектный диск Maxtor после такого форматирования безошибочно проходил все тесты, но работал до первой ошибки не больше недели. Все равно пришлось его отослать в Ирландию производителю для замены на новый.
В корпоративные блоги принято писать success story - это положительно влияет на образ компании. К сожалению, не всегда в работе инженера всё заканчивается happy end-ом.
Надо сказать, что коллеги уже начинают подшучивать, что я «притягиваю» проблемы. Тем или иным образом я поучаствовал почти во всех проблемных заявках за последнее время. И теперь хочу рассказать одну поучительную историю из своей практики.
История началась с того, что меня попросили проанализировать производительность дискового массива одной СХД, «тормоза» которого парализовали работу целого филиала. Исходная ситуация такая:
- На массиве находятся датасторы VMware-фермы.
- Все тома располагаются на RAID5 (диски 7200 и 10000) и зеркалируются между двумя идентичными массивами.
- Контракта с ведором на поддержку этого оборудования нет.
- Версия прошивки массива - 7.3.0.4 (актуальная на тот момент 7.6.1.1).
- Также СХД используется для виртуализации СХД HP EVA.
И тут в ходе анализа производительности начал проявляться «полтергейст»: у томов с массива в интерфейсе vSphere периодически отображается неверный объём (от отрицательного до десятков петабайт), что заказчик расценил как проблему в массиве. При этом пропадал доступ к консолям части виртуальных машин, и возникают другие неприятности. Даже я уже начал нервничать, а заказчик просто в ауте.
И тут начинается просто фейерверк проблем.
Мы нашли баг ESXi, из-за которого могут отображаться неверные размеры томов. Но выясняется, что официального контракта на поддержку VMware нет. Поддержка осуществляется сторонней компанией и только по рабочим дням, а дело происходит в субботу.

Для полного счастья, прошивки двух серверов из трёх и коммутаторов (блейд-шасси) отстают от прошивки модуля управления шасси, что тоже может приводить к самым неожиданным проблемам. Ну и вишенка на торте: на коммутаторах SAN стоят разные версии прошивок, и все позапрошлой мажорной версии (6.x.x, когда доступна 8.0.x).
Напоследок выясняется, что в MS SQL Server Express закончилось свободное место, из-за чего возник «полтергейст» с доступностью консолей VM в vSphere и неверно отображались размеры томов. Так что пока администраторы решали проблемы БД, мы пытались разобраться с СХД.
После некоторых действий основной том вдруг ушёл в оффлайн.
Мы вспоминили про баг в прошивках СХД версий 7.3, 7.4 и 7.5, из-за которого на сжатых томах после определённого количества обращений могут появиться битые блоки (в этой ситуации не может помочь ни отказоустойвость RAID, ни зеркалирование томов на соседний массив, так как ошибка находится уровнем выше).
И вот тут проявился самый интересный нюанс: оказывается, что СРК у заказчика не работает уже 3 месяца. То есть бэкапы есть, но они не актуальные, и восстанавливаться из них - всё равно, что потерять данные.
Нам удалось перевести том в онлайн (через CLI массива), но при первой же попытке хоста что-то записать, он снова упал. Мы отключили все датасторы на серверах и следующие сутки провели в офисе, почти не дыша копируя все виртуальные машины куда получится - на серверы, USB-диски и ПК.
В результате нам удалось спасти все данные, кроме ВМ, на которой запустили консолидацию снапшотов, так как в процессе консолидации LUN ушёл в оффлайн, и вместо данных ВМ осталась «каша». По закону подлости это оказалась ВМ электронного документооборота. Кроме того, для исключения разных рисков пришлось обновить почти всю инфраструктуру - VMware, Brocade, HP Blade и так далее.
Предпосылки катастрофы
Какие выводы может сделать из этой истории уважаемый читатель, чтобы не оказаться в подобной ситуации?
Спасибо за внимание, работы вам без сбоев.
Алексей Трифонов